作者:互联网观察
发布时间:May 18, 2023
分类:互联网观察,linux,技术
ChatGPT是一款高度智能化的聊天机器人,由GPT-3.5 API支持。它可以通过对话了解用户的需求和问题,并为用户提供有用的帮助和指导。许多人都在寻找一款像ChatGPT这样的聊天机器人,以便更轻松地解决问题和获取信息。
对于那些想要下载ChatGPT并使用它的人来说,有很多不错的资源和信息可以查找。首先,可以在互联网上搜索关键字ChatGPT下载,以找到最新版本的下载链接。此外,还可以找到许多有用的资源和指南,以帮助用户更好地使用这个聊天机器人。
作为一款高度智能化的服务,ChatGPT的价格因其含有的服务功能而异。因此,如果您对ChatGPT的服务感兴趣,需要联系外面咨询有关价格的信息。与我们的联系将为您提供完整的信息,了解不同服务的价格,并找到适合您的服务选项。
总的来说,ChatGPT是一款非常有用的聊天机器人,正变得越来越受欢迎。通过使用ChatGPT,用户可以更轻松地解决问题和获取信息。如果您正在寻找一款聊天机器人,并且对ChatGPT的服务感兴趣,为了了解服务的具体价格,建议您联系我。
我将专业为您提供带注册,使用,服务。
作者:互联网观察
发布时间:December 31, 2014
分类:互联网观察,linux,技术
无意中把 worker_connections设置的超大655350,结果,系统内存占用超多,交换区都快被沾满了。
将worker_connections设置为65535 后,问题解决。
作者:互联网观察
发布时间:May 28, 2014
分类:linux,技术
OneThink内容管理框架 基于ThinkPHP3.2新版 PHP开发最佳实践... OneThink将成为继ThinkPHP之后,另一面国产开源旗舰产品。
onethink非常适合二次开发网站,管理系统,发布系统等等定制系统。
提供onethink开发服务,联系:[email protected]

作者:互联网观察
发布时间:November 20, 2013
分类:默认分类,技术
[e:loop={'selfinfo',1,0,0,'firsttitle=5'}]
<li class="mr20">
<h5>
<a href="<?=$bqsr['titleurl']?>" target="_blank" class="mingray"><?=$bqr['title']?></a>
</h5>
<p class="info_txt">
<?php
$fr=$empire->fetch1("select ztext from {$dbtbpre}ecms_txt_data_{$bqr[stb]} where id='$bqr[id]'");
?>
<?=$fr['ztext']?>
</p>
</li>
[/e:loop]
作者:互联网观察
发布时间:March 22, 2013
分类:技术
一般来说是根据你这个app的功能,开发周期,实现难易度来得出这个开发费用的。和软件开发是一样道理的。专业App开发,ios android symbian wm等.
是3D的吗?如果是3D的话,费用以万为单位,具体还要看有哪些功能。
对于iOS应用开发者来说,在将其产品发布到App Store上还得投入大量的营销费用来争取用户。对此SearchMan公司特研究开发了一款名为SearchMan SEO的搜索引擎优化工具来帮助开发者在App Store中搜索跟踪及关键字优化以保证其应用在用户搜索时能排在前列。
开发者:怀念iOS 5的好
相比较iOS 6的App Store,开发者们更喜欢iOS 5。在iOS 5 App Store中,用户在搜索结果中可以看到5个应用,并且用手指轻轻一弹就可以立即看到与搜索相关的25个应用。但在iOS 6版本的App Store中只能看到一款应用的搜索页面,这也就意味着原本位居搜索结果前100名的应用将更难获得用户的关注。
对于想要通过强大的功能增强创意的iOS开发人员和iOS平台开发新手,该应用都是必备应用。
注意:
- 要开发iOS程序,您需要有一台Mac系统的电脑。
- 若要理解和运用该应用中包含的代码,您需有一定编程知识(特别是Objective-C语言)。

作者:互联网观察
发布时间:February 18, 2013
分类:技术
这个工具可以将您的mht,nws,eml文件批量转换为html文件。
- 批量转换
- 快速
- 智能
MHTML stands for MIME HTML. It is a standard for including resources that in usual HTTP pages are linked externally, such as images and sound files, in the same file as the HTML code. The included data files are encoded using MIME. This format is sometimes referred to as MHT, after the suffix .mht given to such files by default when created by Microsoft Word, Internet Explorer or Opera. (Some people feel this is improper usage.
The key to MHTML is that the content is encoded as if it were an email message, using the MIME type multipart/related. The first part is the HTML file, encoded normally. Subsequent parts are additional resources, identified by their original URLs
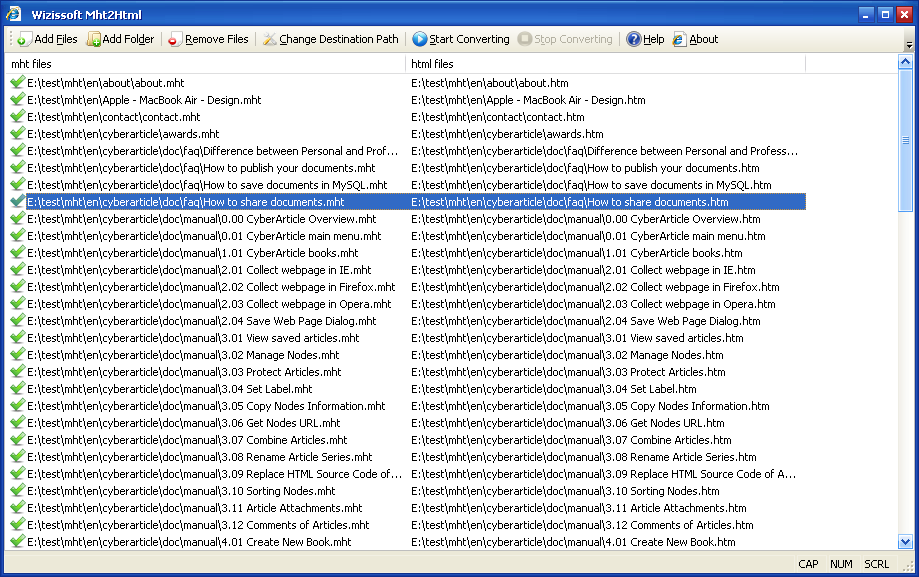
下载地址:http://wizbrother.net/downloads/tools/mht2html-1.0-2009-6-2.zip
作者:互联网观察
发布时间:February 4, 2013
分类:生活,技术
完成客户的项目。
利用30天时间学习IOS并且做3+个IOS+后端server项目。并且开源。
学习arduino 读作:“阿迪诺欧”
学习Linux

作者:互联网观察
发布时间:February 4, 2013
分类:linux,生活,技术
2012年发生了很多,从辞职被拖欠薪水,到被气病,到武汉之旅,天津之旅,无力的沉默。
2012年发生了很多,从朋友,到客户。
现在,马上就要过年了,过去的2012年是个很特别的一年,这一年我赚到了人生最高的月薪,也再一次开启我的创业之旅。很明显,这次要游刃有余的多,但也更要感谢我过去的领导:王经理,的支持。和过去的老师的一次再一次的相信。虽然她的项目过了年就要上线直到现在只还存在一个半成品。一定要在学校开学前完成项目,就算可以简单的使用也好!就要做削减功能了。不能让老师在担心了。今天是2月4号。9号是除夕。那么。从今天开始的 4,5,6,7,8 五天,我将全部用在老师的项目上。
最近睡的很晚,经常 凌晨,3,4点才睡着。造成这样的原因是,之前1,2,点睡,然后就一天比一天睡的晚了。。。
熬夜的确是个很消耗身体的事情,消耗的不是体能,是精神。整个人很没精神。
最近发现了 raspberry pi arduino mk802 这些平台。以及各种传感器。发现这种传感器比我想象的要开发容易的多。各种部件,接口,处理器,几乎都可以在网上买到,也可以找到示例代码,并且还有开源平台,有了这些传感器就可以开发出很多有趣,并且可以改变人类的东西,在这提到,这些东西几乎都运行在linux 或类unix下。可以肯定的说,做这类开发,必定要用到linux。并且,raspberry pi arduino mk802 这些设备都非常受益于开源 。开源的图纸,开源的硬件,开源的驱动。
从前对于开源只理解到源代码开放免费使用,现在来看,开源对于世界来说,就等于自由。你绝对不希望你在开发传感器应用的时候要花钱买各种驱动各种软件。如果整个环境都是封闭的,不会有丰富的智能产品出现。
扯远了。2012。动荡的一年。2013,冒险的一年。2013年,维系住客户,开发新客户,学习IOS ,学习 linux,arduino。

作者:互联网观察
发布时间:February 1, 2013
分类:linux,技术
原创转载请标注!
将 搜索代码 换成如下代码
<form method="get" target = "_blank" action="http://www.google.com.hk/search?q=site%3Awww.tianmeng.org">
<input type="hidden" value="site:www.tianmeng.org" name="q"/>
<input type="text" value="" name="q" id="s" />
<input type="submit" class="submit" value="搜索">
</form>
将www.tianmeng.org换成你自己的域名。
作者:互联网观察
发布时间:January 28, 2013
分类:技术
最近发现dedecms 的编辑器没有了附件按钮。仔细查找发现dedecms的编辑器加了后门,与其说是后门不如说是一个奇怪的统计用户或者爆后台地址的东西。因为,编辑器中的大多数按钮用的是你所安装的服务器本地的gif按钮图片。
但是,附件这个按钮用的 是 dedecms 自己的网站的图片引用地址。
经过分析我发现址是:http://desdevcms.com/images/addon.gif?t=xxxx
其中的XXX 是一串代码,具体含义不知,应该是代表某种用户标签。
问题出来了,他的这个图片挂了。。根本无法显示了。于是在后台编辑器中附件就是空的,这再ie中可能是叉子。
并且,在dedecms的编辑器的css里面居然没有定义这个按钮的图片。发现在图片文件中是有这个图片的。
下面是修改办法。
修改编辑器目录中插件文件夹下的addon下的plugin.js 去掉其中 icon:http://desdevcms.com。。。。这行。
然后打开编辑器css ,目录是skins\kama\deitor.css 在尾部添加代码
.cke_skin_kama .cke_button_addon .cke_icon{background-position:0 -686px;}
上传到服务器,ok,搞定,附件图片出现了。
在这深深的对dedecms不发表意见。。。这。。。
作者:互联网观察
发布时间:January 10, 2013
分类:技术
写了个python爬虫,网络方面性能很好,爬到的数据写入数据库中。
但是问题来了,写入了大概2w行之后报错。错误内容是:
'int' does not support the buffer interface
问题出现在int的一个转换问题。解决办法如下:
修改Python32\site-packages\pymysql\connections.py 文件中的
unpack_int24
unpack_int32
unpack_int64
三个函数。修改成下面样子
def unpack_int24(n):
try:
return struct.unpack('B',n[0])[0] + (struct.unpack('B', n[1])[0] << 8) +\
(struct.unpack('B',n[2])[0] << 16)
except TypeError:
return n[0]+(n[1]<<8)+(n[2]<<16)
def unpack_int32(n):
try:
return struct.unpack('B',n[0])[0] + (struct.unpack('B', n[1])[0] << 8) +\
(struct.unpack('B',n[2])[0] << 16) + (struct.unpack('B', n[3])[0] << 24)
except TypeError:
return n[0]+(n[1]<<8)+(n[2]<<16)+(n[3]<<24)
def unpack_int64(n):
try:
return struct.unpack('B',n[0])[0] + (struct.unpack('B', n[1])[0]<<8) +\
(struct.unpack('B',n[2])[0] << 16) + (struct.unpack('B',n[3])[0]<<24)+\
(struct.unpack('B',n[4])[0] << 32) + (struct.unpack('B',n[5])[0]<<40)+\
(struct.unpack('B',n[6])[0] << 48) + (struct.unpack('B',n[7])[0]<<56)
except TypeError:
return n[0]+(n[1]<<8)+(n[2]<<16)+(n[3]<<24) \
+(n[4]<<32)+(n[5]<<40)+(n[6]<<48)+(n[7]<<56)
修改 完成后保存。好了,问题解决了。。
作者:互联网观察
发布时间:January 8, 2013
分类:技术
在分布式海量存储系统中,算法也发挥着重要的作用,本章分享的是在nosql等海量存储中两个比较重要的算法:The Log-Structured Merge-Tree(简称LSM-tree)、Bloom filter。这两个算法在bigtable、leveldb、cassandra、hbase等存储系统中都有用到。
The Log-Structured Merge-Tree
LSM-Tree软件解决方案的基本原理都非常简单,就是在内存中对最近的更新操作进行缓存,当更新积累到一定程度,然后进行批量的merge dump,从而把随机写变成批量顺序更新。
对于LSM-Tree,
拿update举个例子:
比如有1000万行数据,现在希望update table.a set addr='new addr' where pk = '833',
如果使用B-Tree类似的结构操作,就需要:
1. 找到该条记录所在的page,
2. load page到内存(如果恰好该page已经在内存中,则省略该步)
3. 如果该page之前被修改过,则先flush page to disk
4. 修改数据
上面的动作平均来说有两次disk I/O,
如果采用LSM-Tree类似结构,则:
1. 将需要修改的数据直接写入内存
可见这里是没有disk I/O的。
当然,我们要说,这样的话读的时候就费劲了,需要merge disk上的数据和memory中的修改数据,这显然降低了读的性能。
确实如此,所以作者其中有个假设,就是写入远大于读取的时候,LSM是个很好的选择。我觉得更准确的描述应该是”优化了写,没有显著降低读“,因为大部分时候我们都是要求读最新的数据,而最新的数据很可能还在内存里面,即使不在内存里面,只要不是那些更新特别频繁的数据,其I/O次数也是有限的。
所以LSM-Tree比较适合的应用场景是:insert数据量大,读数据量和update数据量不高且读一般针对最新数据。
文章读下来有以下几点感受:
1. 基本思想早就有了,作者给出了较好的表现形式。
2. Merge是page/block级别的,而不是BigTable中的文件级别的。这一点主要原因可能是BigTable在分布式场景下做block级别很困那,而且GFS也不支持修改。
3. 其提出的比较标准比较有趣,将磁盘容量,转速等结合起来给出一个以美元为单位的cost标准,然后跟B-Tree结构的实现做了比较,结果当然是大大胜出。但是这里我觉得作者有些比较是不合理的,比如LSM使用log而B-Tree没有使用,这显然对B-Tree不公,其实B-Tree如果使用log,写入性能应该不比LSM差,顺序读取可能差一些。
4. 在Multi components 中,提出Ci/Ci+1的比例达到20的时候是最优的,这个数字意义不大,但是其中的分析方法对于Merge策略的选择是个启发。

作者:互联网观察
发布时间:March 26, 2012
分类:技术
高效标准的图片预加载,预读取
<script>
var myImages =
[
'images/1.jpg',
'images/2.jpg'
];
for(var i = 0; i < myImages.length; i++)
{
var img = new Image();
img.src = myImages[i];
}
</script>
作者:互联网观察
发布时间:October 30, 2011
分类:技术
xbox 好友批量下载器。
xbox 账户资料下载器。批量下载账户好友id
xbox friendcenter下载器。
xbox扫号器。扫描好友信息。
需要请联系QQ:859258522
作者:互联网观察
发布时间:July 17, 2011
分类:技术
在主程序中 import lxml._elementpath 就可以了。。。
- 页码:
- 1
- 2
- 3
- »